| | 
|
At the Univ. of Missouri Dr. Zhuang and Dr. Palaniappan have established a $1.7 million Multimedia Communications and Visualization Laboratory (MCVL) in the Department of Computer Science (formerly CECS) jointly funded by grants from the National Aeronautics and Space Administration (NAG-5-3900, NAG-5-6968, NAG-5-6283, NAG-13-99014), National Science Foundation (96-14 Award 9720668, EIA Award 9911095), National Institutes of Health (R33 EB000573), National Geospatial-Intelligence Agency, Raytheon (C-5-34366) and Silicon Graphics Inc. (SGI).
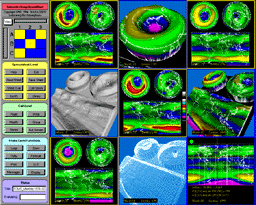
The CS MCVL conducts research and training in a number of areas related to multimedia and graphics including (1) digital video over information networks applied to very low bit rate video coding using the wavelet transform, visual content analysis, coding and retrieval, and intelligent network access to compressed multimedia datasets in digital libraries; (2) scientific visualization applied to the analysis and interactive manipulation of biological and geophysical datasets, video visualization and databases, distributed visualization, biomedical virtual reality, information mining, network topology visualization, and parallel algorithm development; (3) design of robust algorithms for image understanding including deformable motion, multi-view stereo analysis, and scene classification applied to bioimaging (e.g. wound closure, gastrulation, embryogenesis) and remote sensing (e.g. land cover mapping, road following, building extraction).
The MCVL facilities currently consists of current generation Wintel PCs, 4 TB Apple XServe RAID 5 for non-linear video editing, sixteen Silicon Graphics workstations including five Octane2 R14000 workstations with V12 graphics, one Origin/CRAY 2000 supercomputer, a dual Athalon MP Linux-based terabyte RAID 5 storage server, one four processor Onyx2, eight R10000 O2s, four dual processor Octanes with MXI graphics, and two Indigo2s. The MCVL has installed a Fakespace Immersadesk R2 virtual reality display system with a novel VRGlove device. The Origin 2000 includes InfiniteReality2 graphics with two raster managers (64MB and 16 MB of texture memory each), the Onyx2 includes InfinteReality2 graphics with 8 display channels. The rack-based Origin 2000 has a 360 GB Fibre-channel disk array storage system and the Onyx2 has a 54 GB 6-way striped disk array. The Octane and Onyx2 virtual reality workstations have stereo capability and are used to develop 3-D displays using the StereoGraphic CrystalEyes stereo hardware.
The distributed MCVL cluster of workstations contains a total of over 16 gigabytes of memory (RAM), nearly 10 TB of disk storage, over 30 CPUs, a variety of graphics capabilities, with Gigabit Ethernet, 802.1X wireless LAN and 100BaseT network connectivity. A variety of high end networked Pentinum IV Dell, and Compaq PCs are also available. High speed Gigabit Ethernet and ATM switches support distributed computing research over local area wired and wireless networks. Internet access optimized over the NSF vBNS or Internet 2 Abilene research networks is available at OC-3 (155 megabits/sec) or DS-3 speeds. Specialized nonlinear video processing and editing equipment are also available.
![[Atmospheric Panorama]](things/Panorama_md.gif)
 Faculty & Students
Available Facilities
Available Hardware
Available Software
System Adminstration Information
Publications
Courses
MCVL Resources
MCVL Reference Books and Documentation
MCVL User Policy
vslcca_test_sequence
Download
Free Download
Demos
Send mail to Hai Jiang regarding MCVL system administration information.
Faculty & Students
Available Facilities
Available Hardware
Available Software
System Adminstration Information
Publications
Courses
MCVL Resources
MCVL Reference Books and Documentation
MCVL User Policy
vslcca_test_sequence
Download
Free Download
Demos
Send mail to Hai Jiang regarding MCVL system administration information.
 Top ten research facts about Mizzou
UMC is a member of the prestigious Association
of American Universities
Top ten research facts about Mizzou
UMC is a member of the prestigious Association
of American Universities
 UMC highly ranked by U.S. News & World Report (national recognition)
including
Top Publics
and Best Value
UMC Admission Information History (see also National Association of State Univ. and Land-Grant Colleges) UM Four Campus System University of Missouri-Columbia College of Engineering Graduate School CS Graduate Student Forms
UMC highly ranked by U.S. News & World Report (national recognition)
including
Top Publics
and Best Value
UMC Admission Information History (see also National Association of State Univ. and Land-Grant Colleges) UM Four Campus System University of Missouri-Columbia College of Engineering Graduate School CS Graduate Student Forms
 IEEE and
ACM IEEE and
ACM Student Chapter
Columbia, MO is often ranked among the best places to live by Money magazine (as high as second) Missouri Facts & Figures About Columbia, MO , and visitor information from Chamber of Commerce
Current weather
IEEE and
ACM IEEE and
ACM Student Chapter
Columbia, MO is often ranked among the best places to live by Money magazine (as high as second) Missouri Facts & Figures About Columbia, MO , and visitor information from Chamber of Commerce
Current weather
| E-mail comments or requests | 
|